Process Artifacts
Storyboards, Workflows & System Models
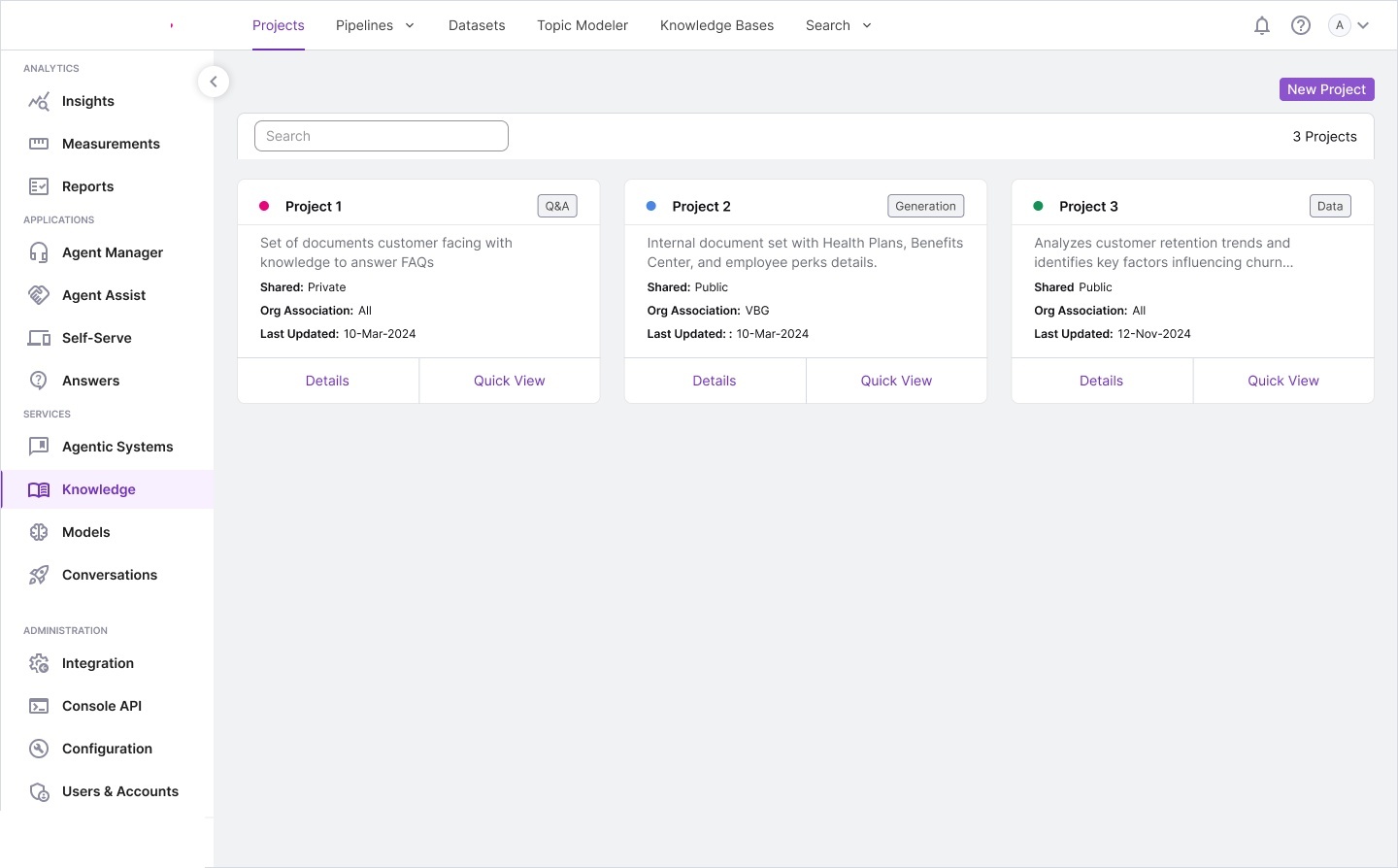
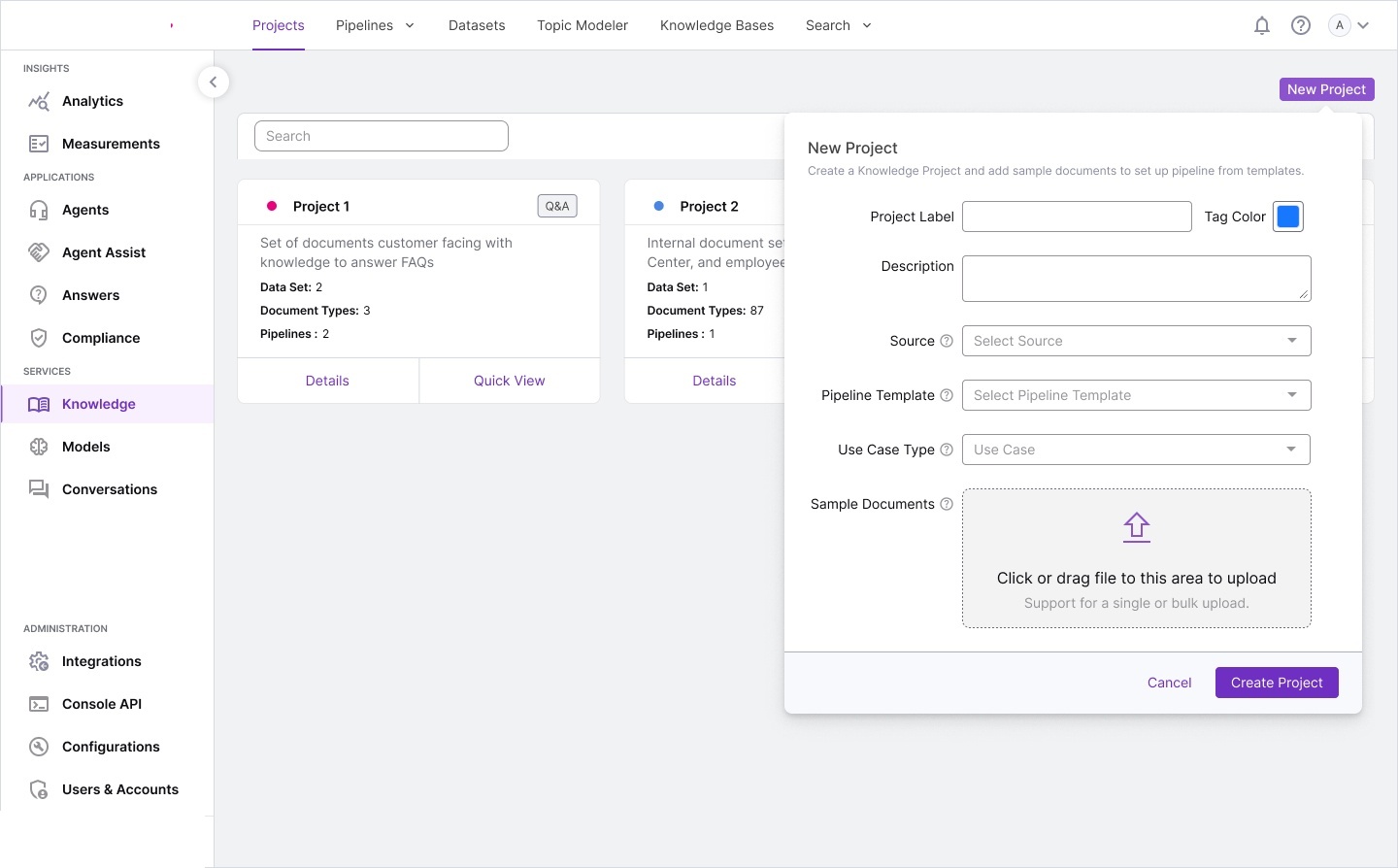
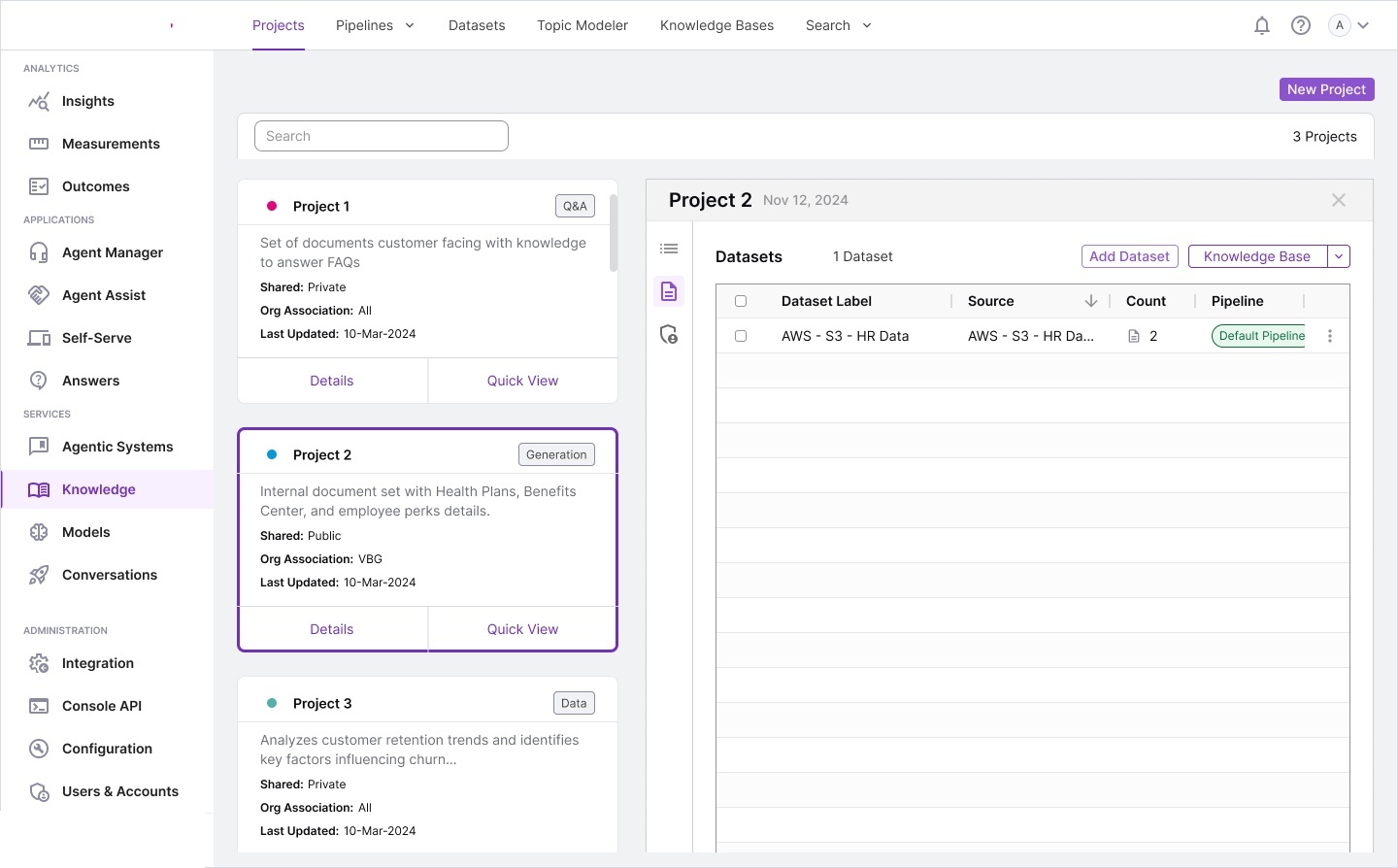
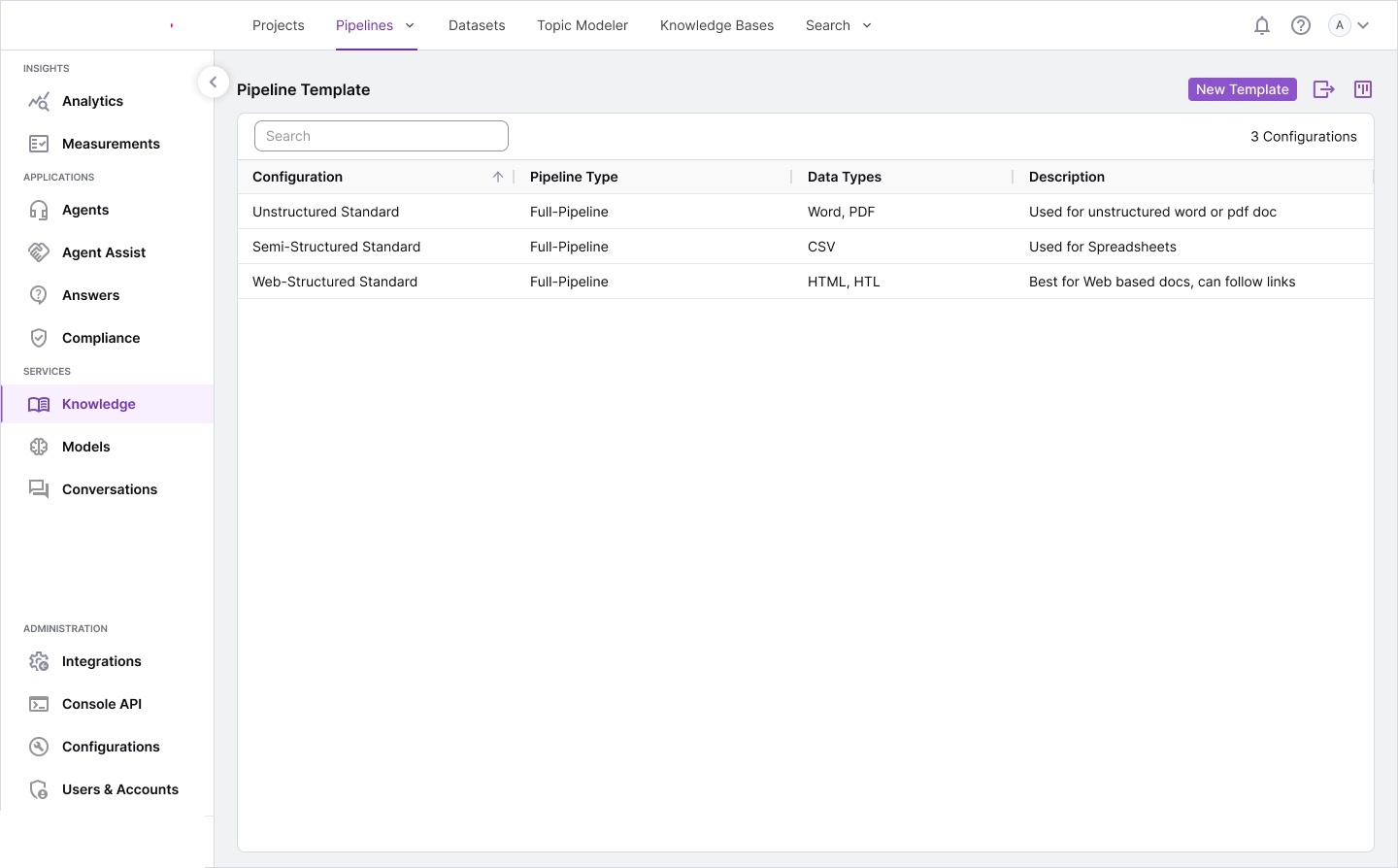
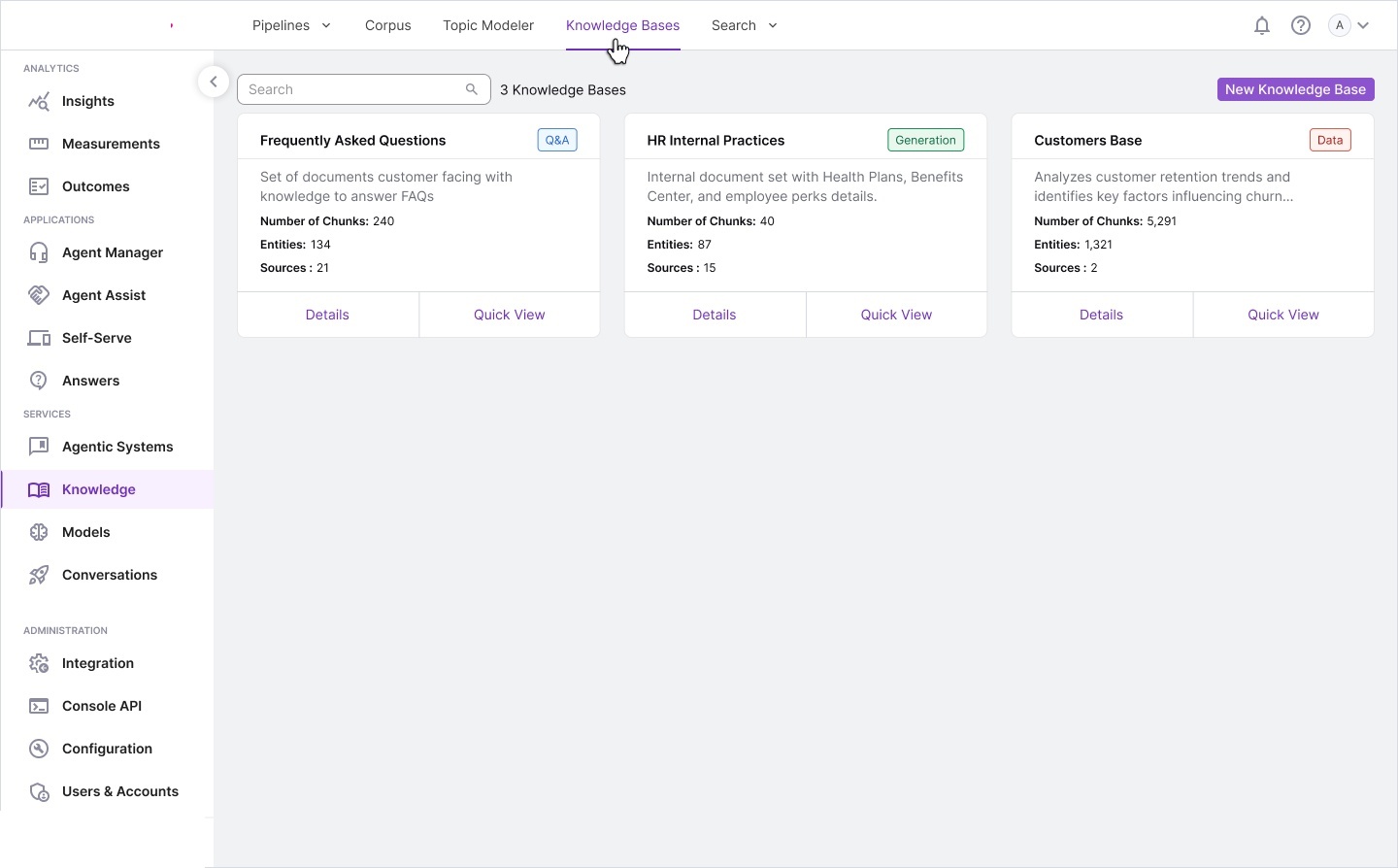
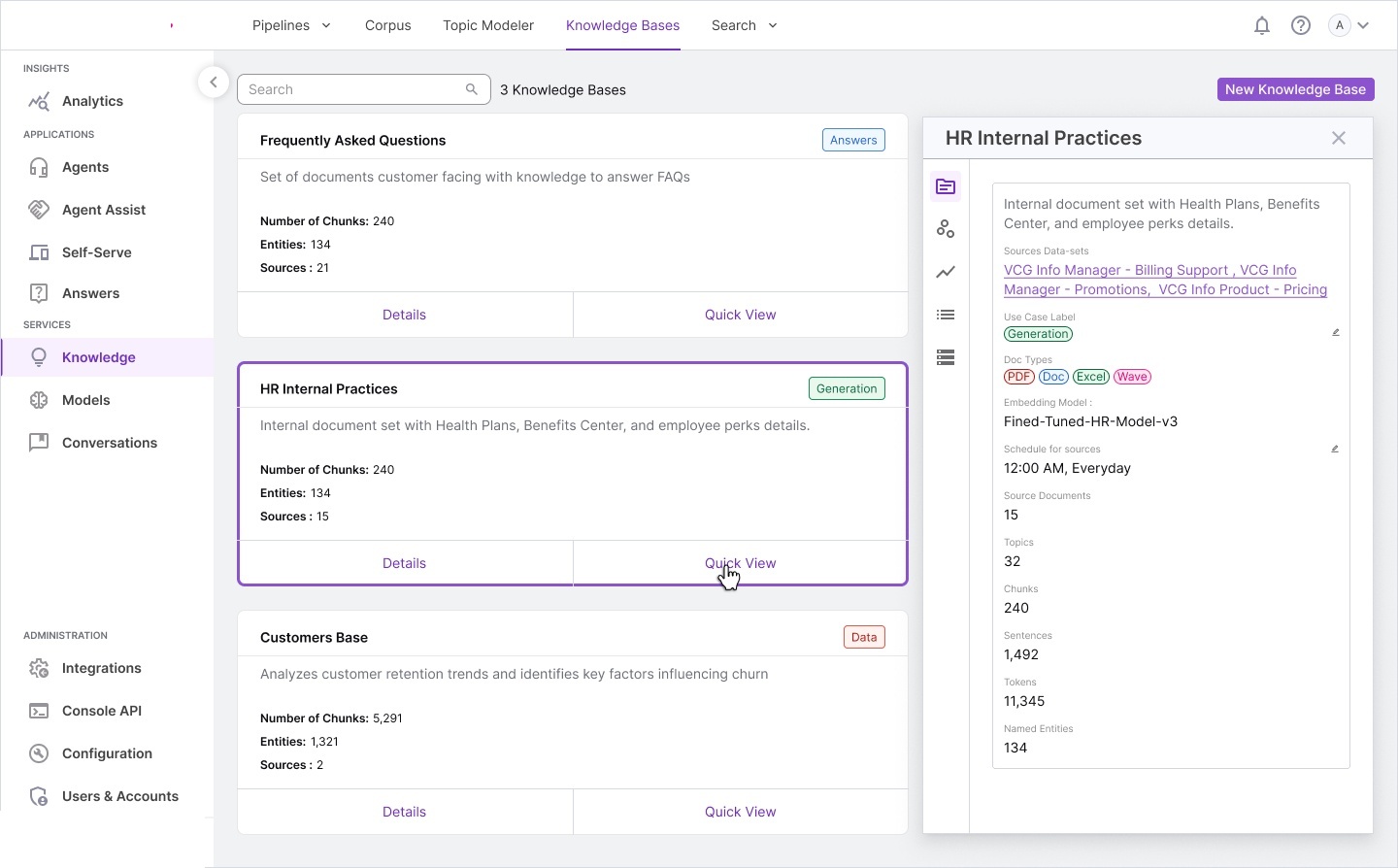
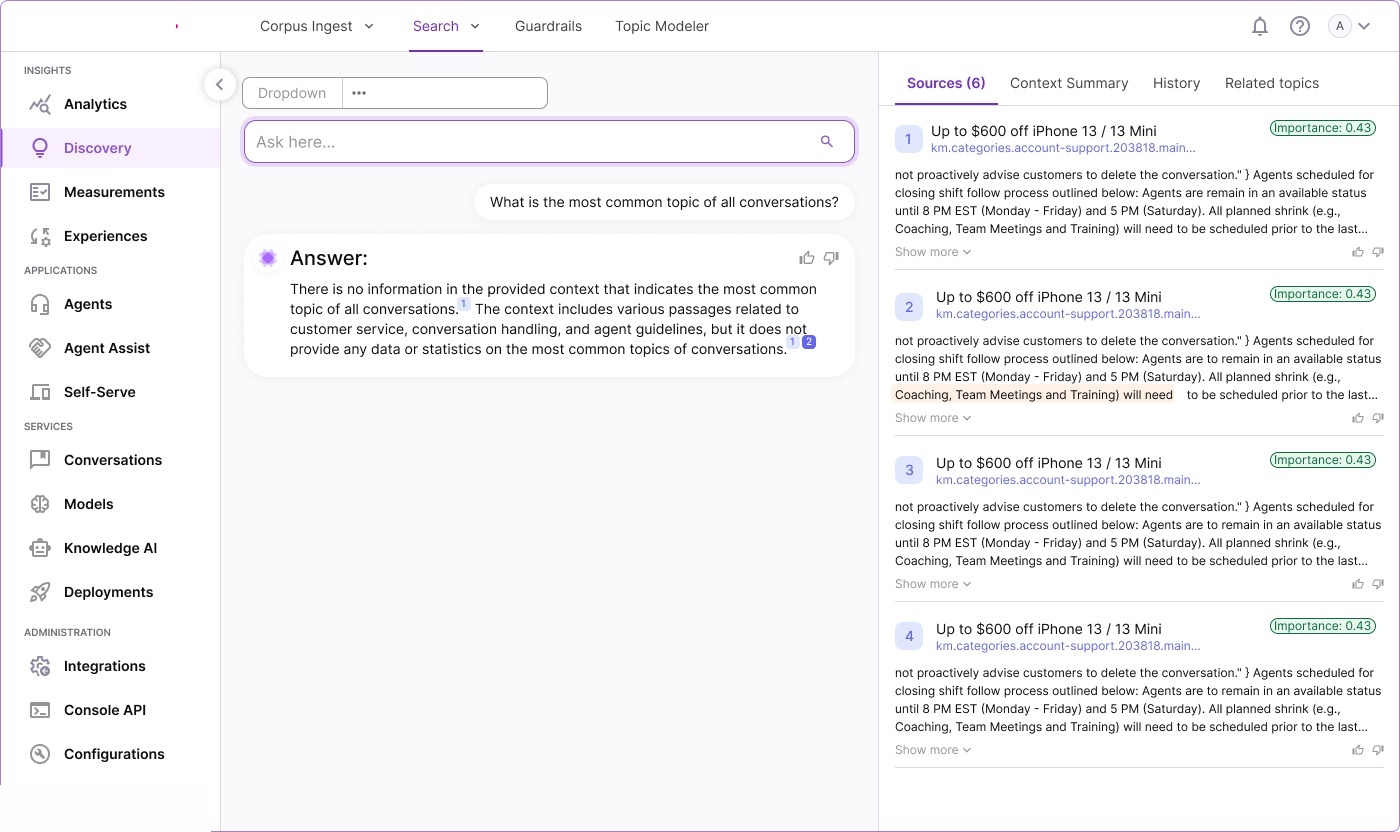
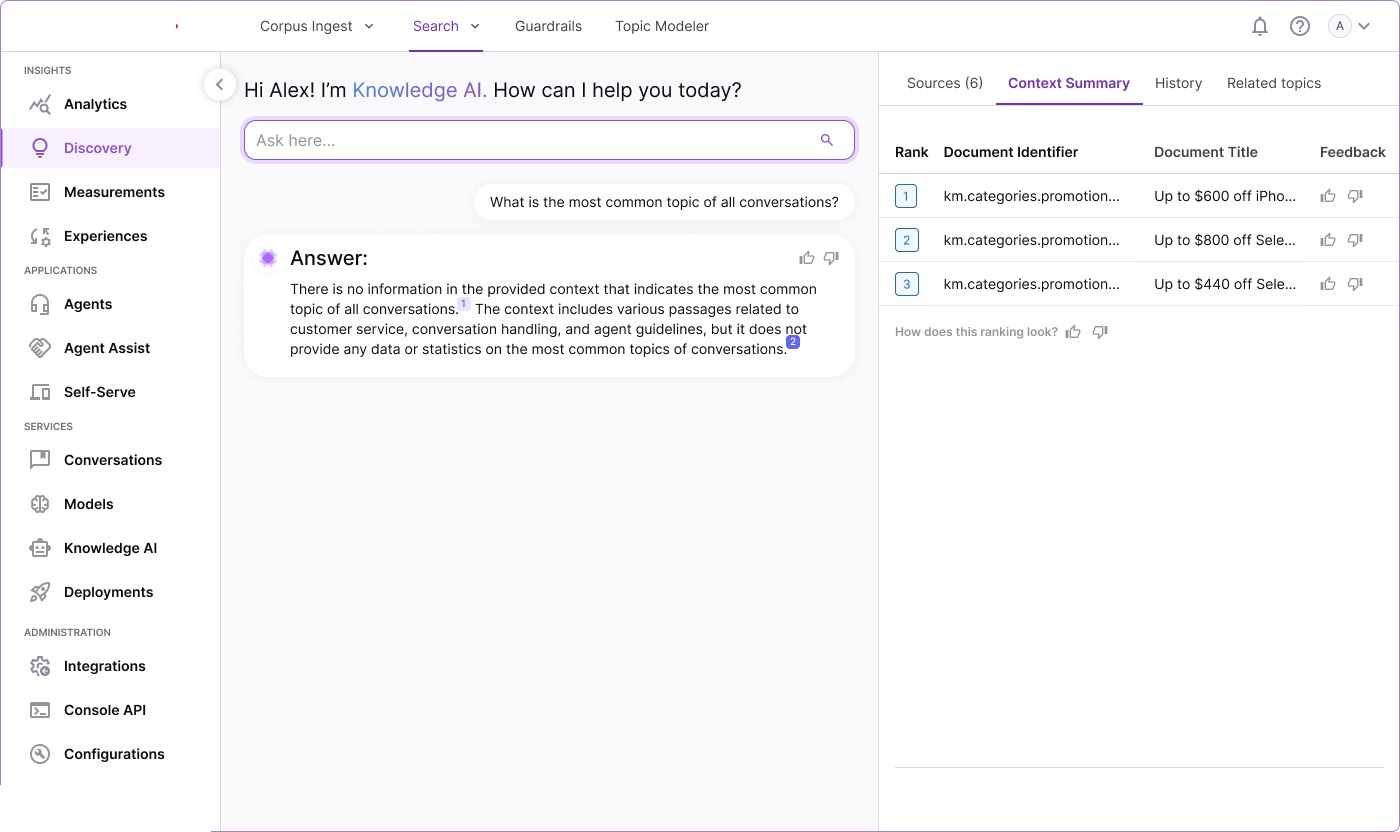
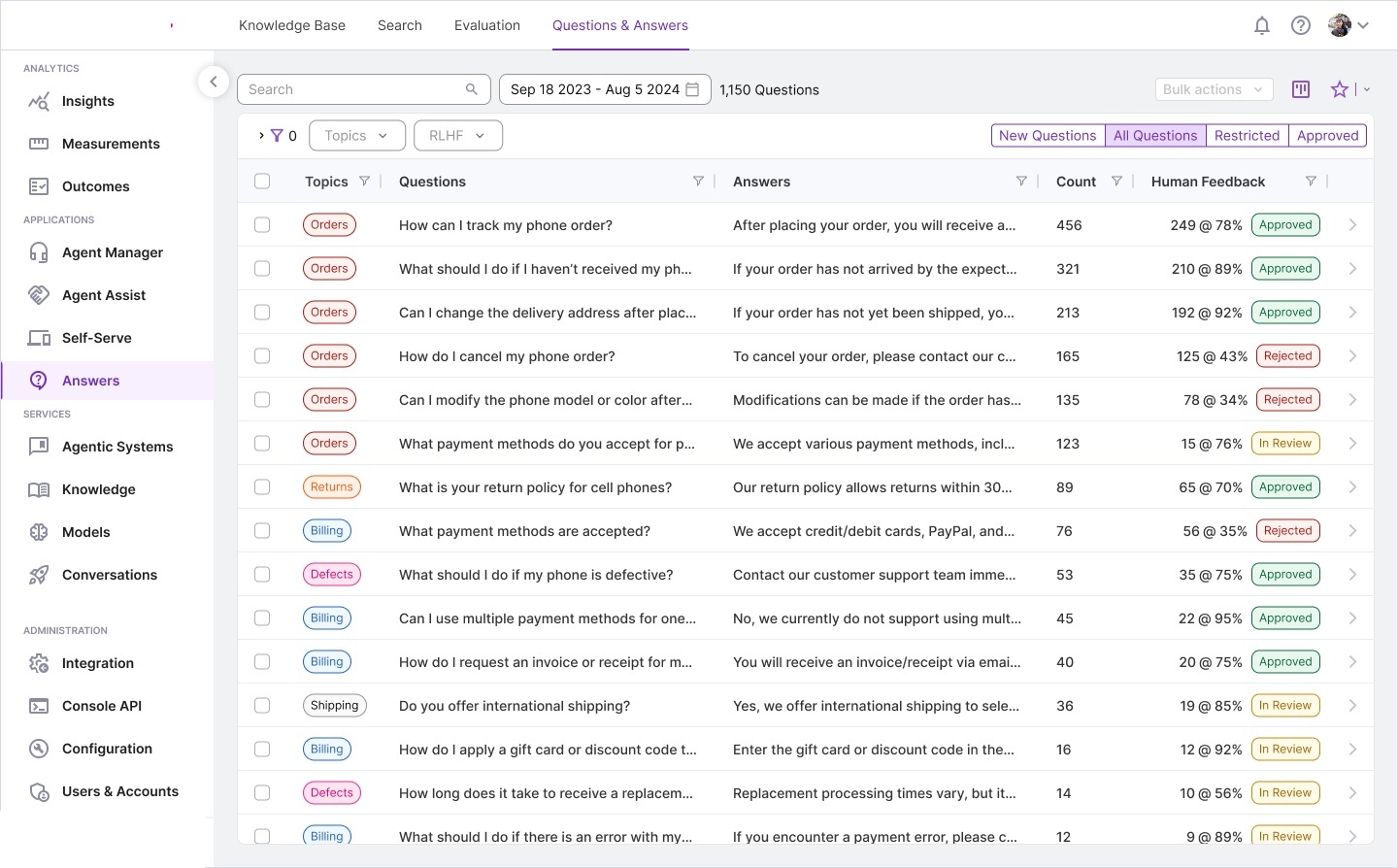
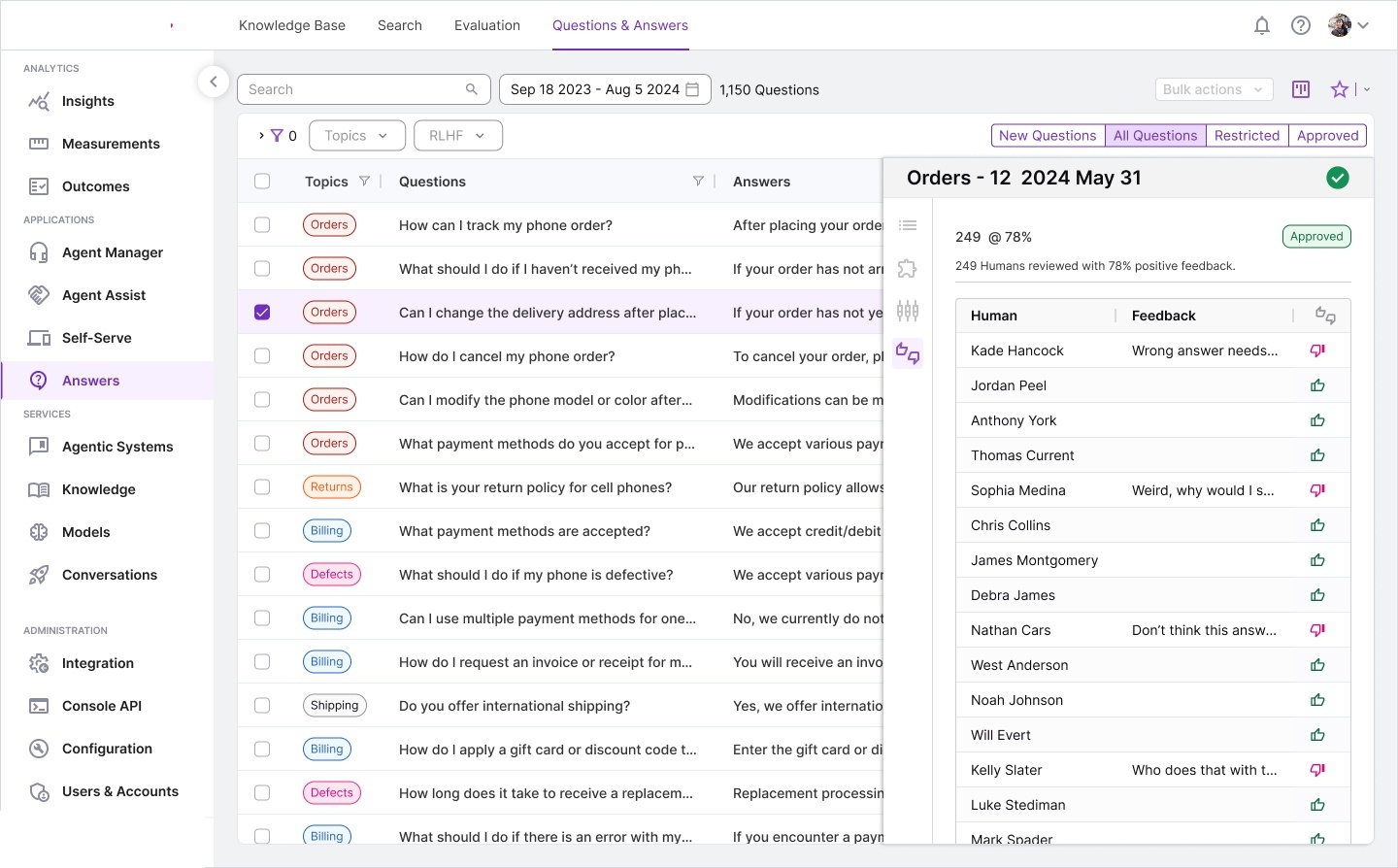
We produced extensive storyboards, information architecture maps, and workflow diagrams during discovery. These artifacts became the foundation for the complete design system.

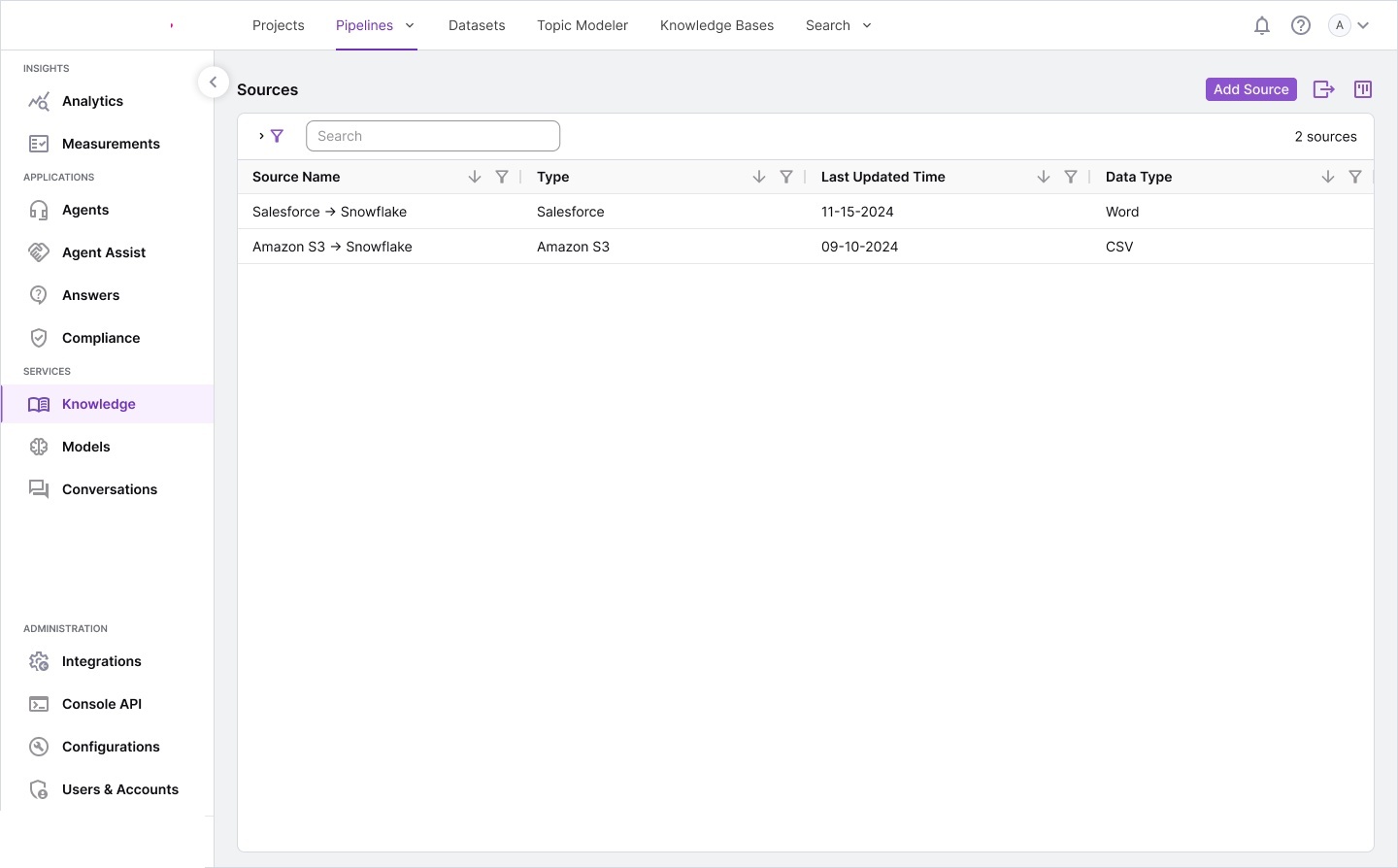
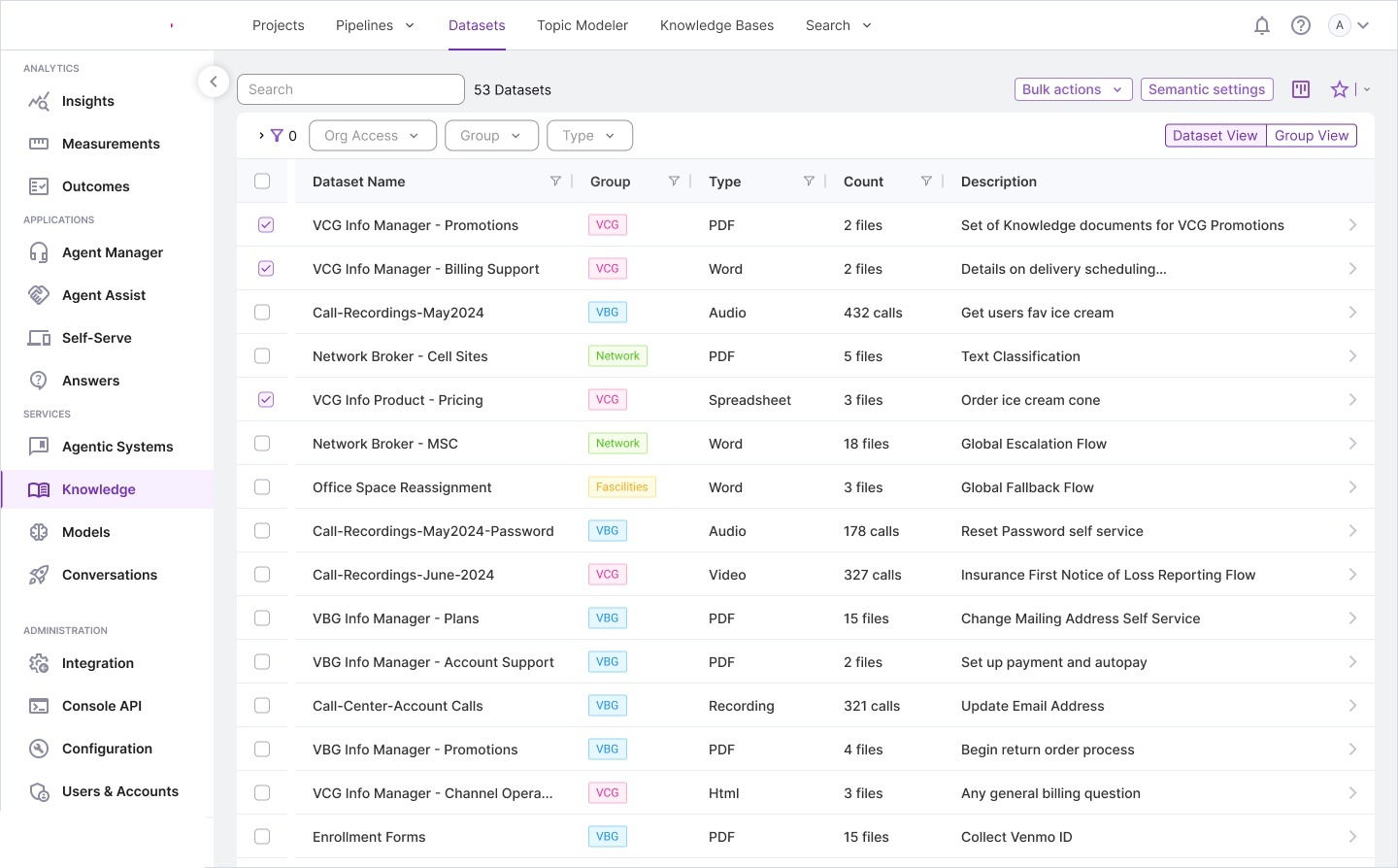
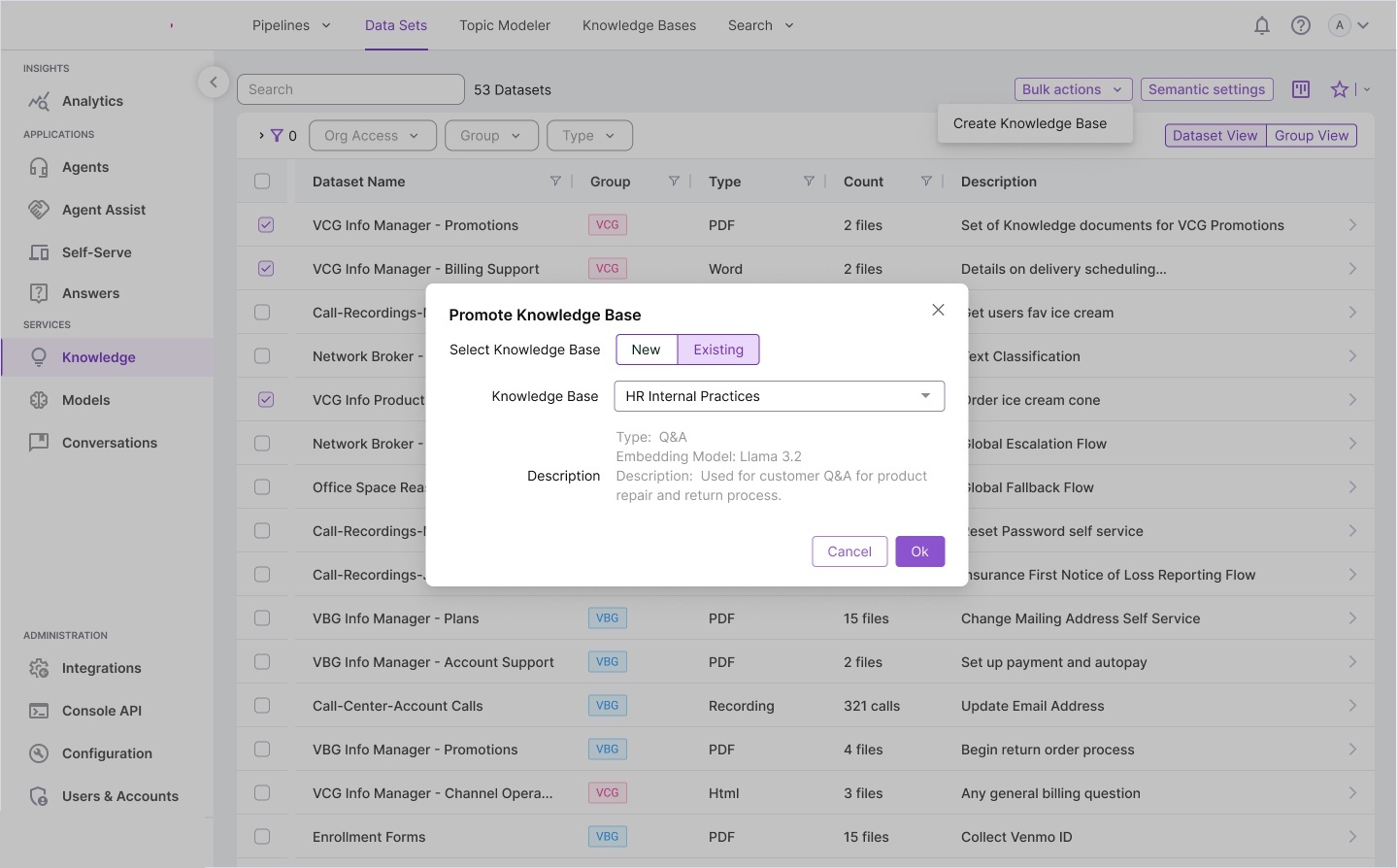
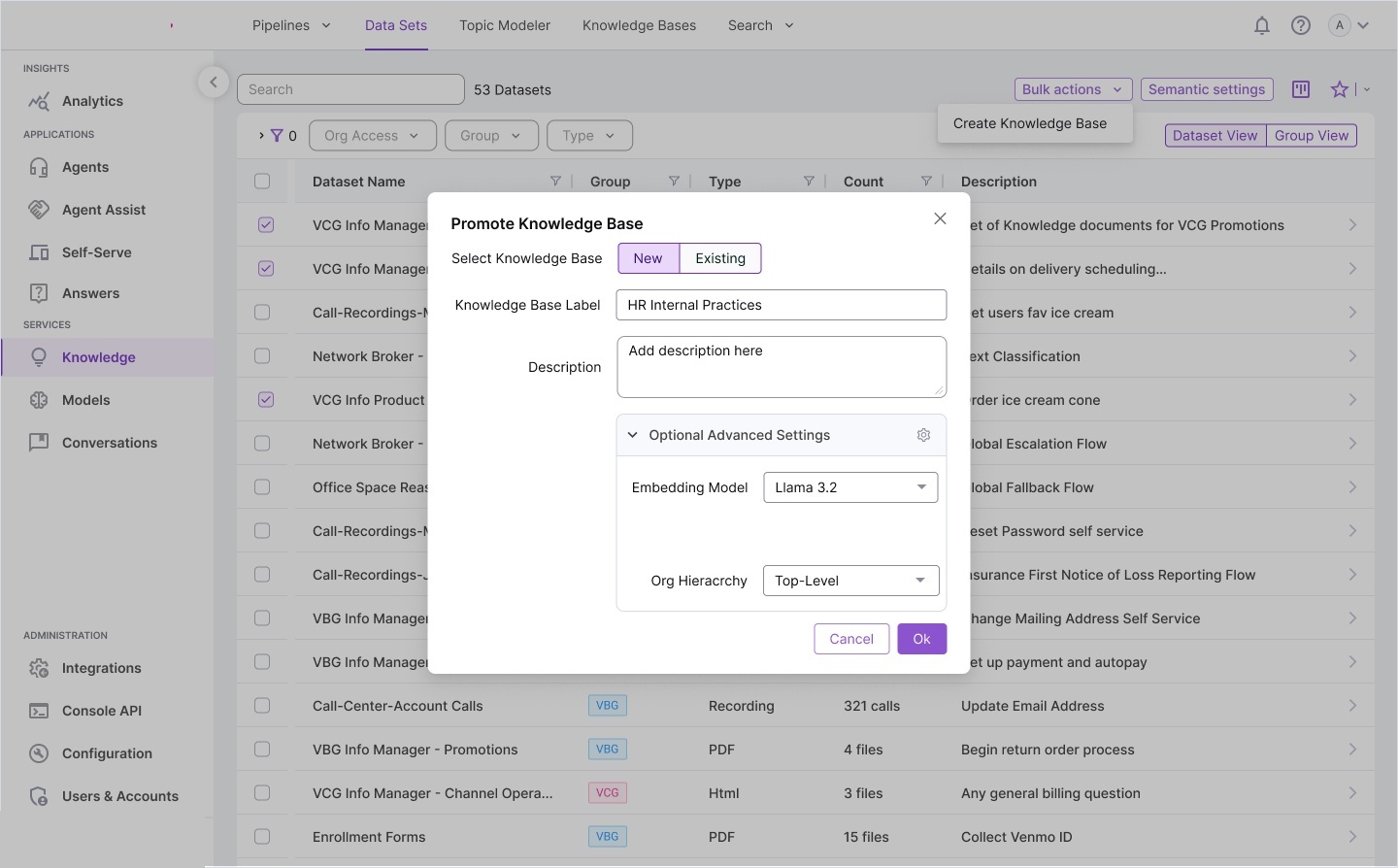
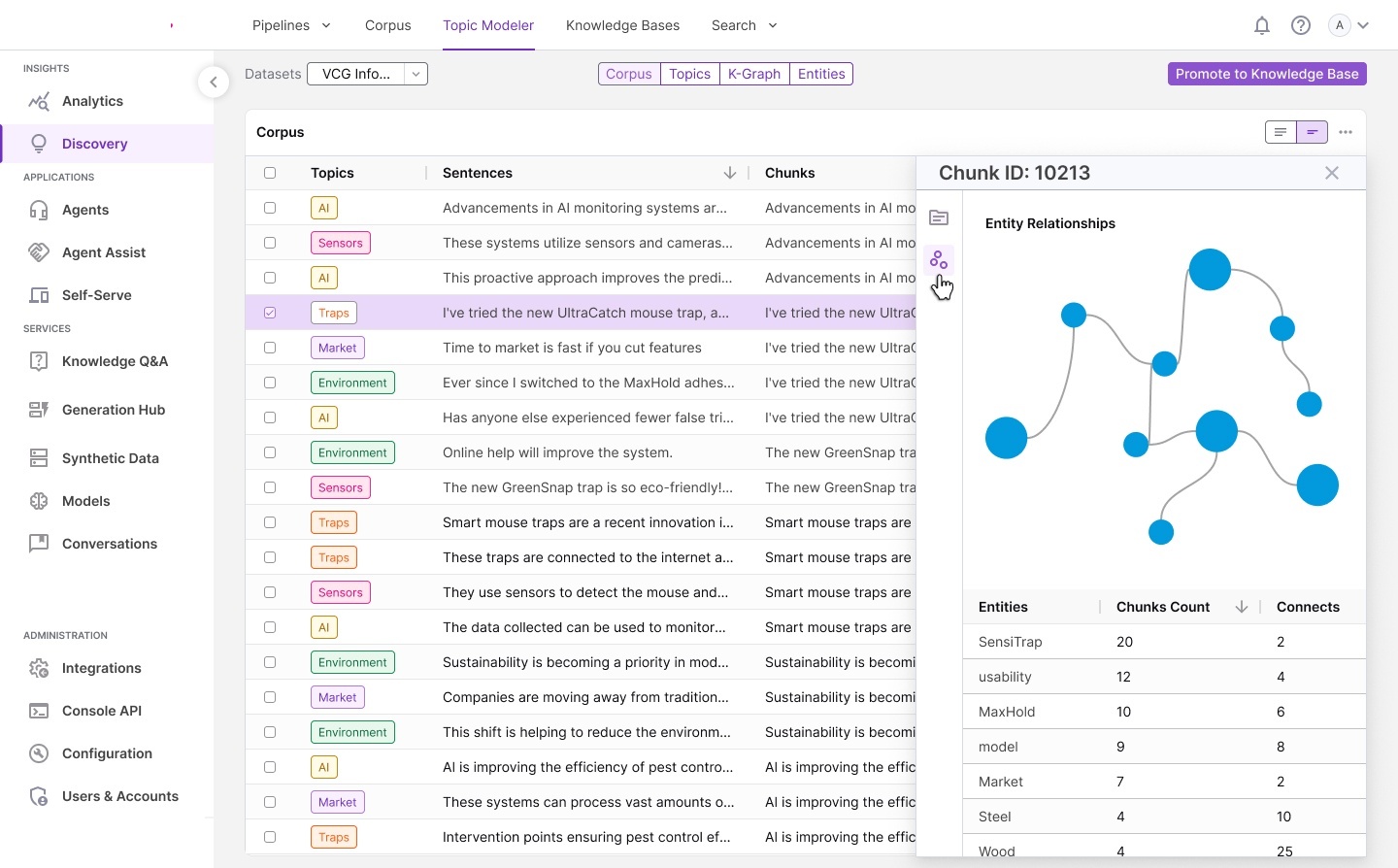
Information architecture — complete system model: ontology structures,
knowledge base design, relationship diagrams, report builder integration, and full screen layout overview.

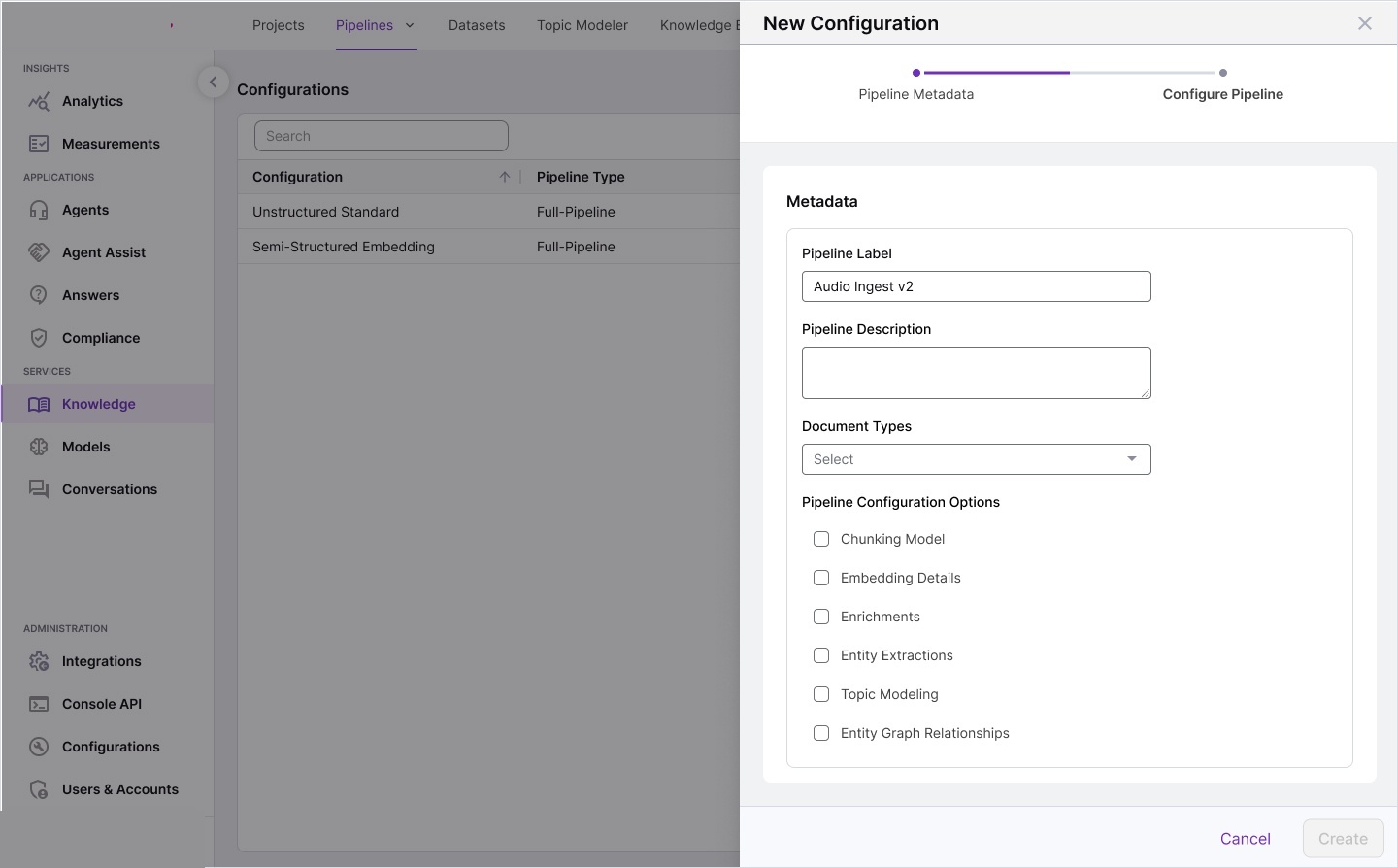
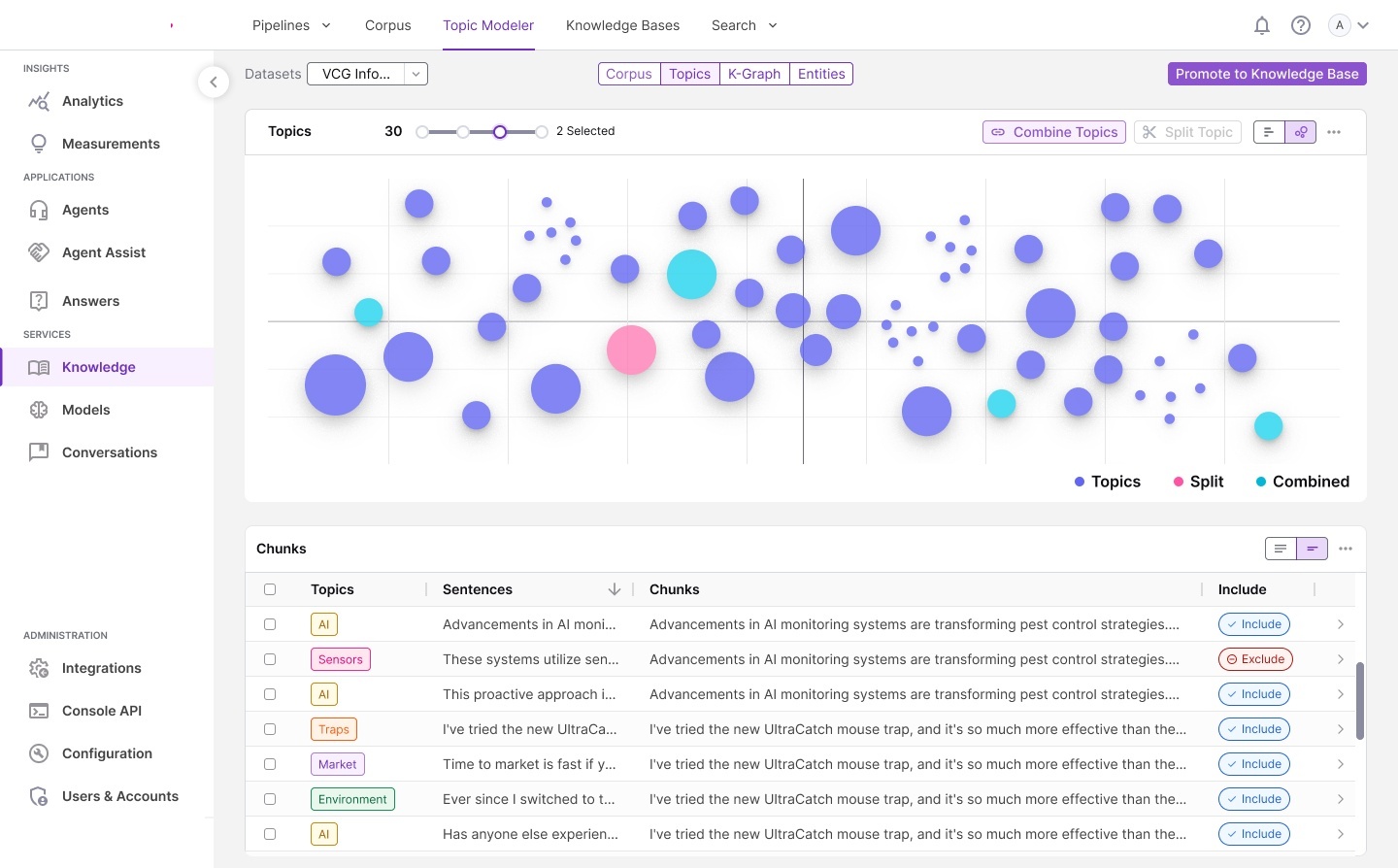
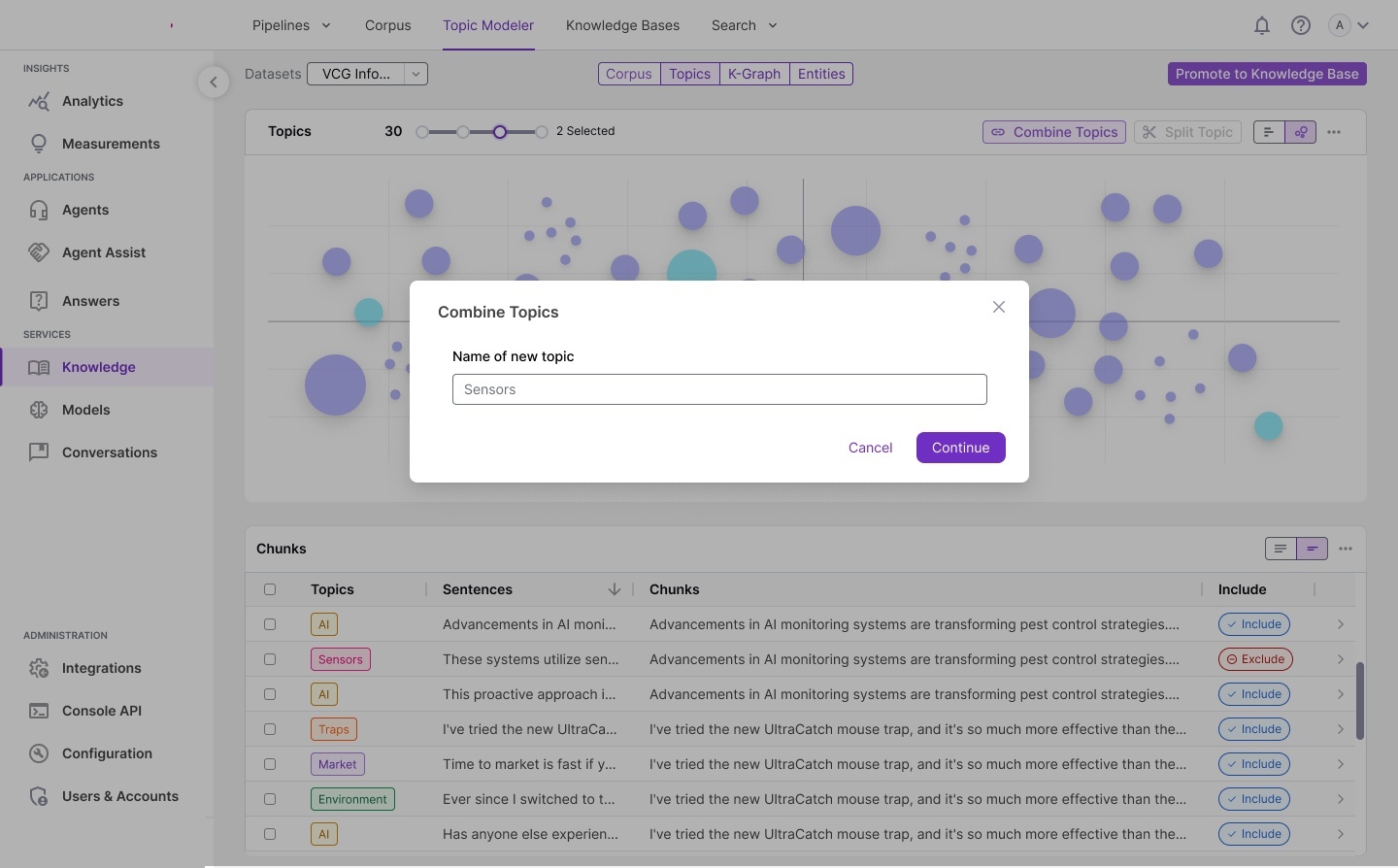
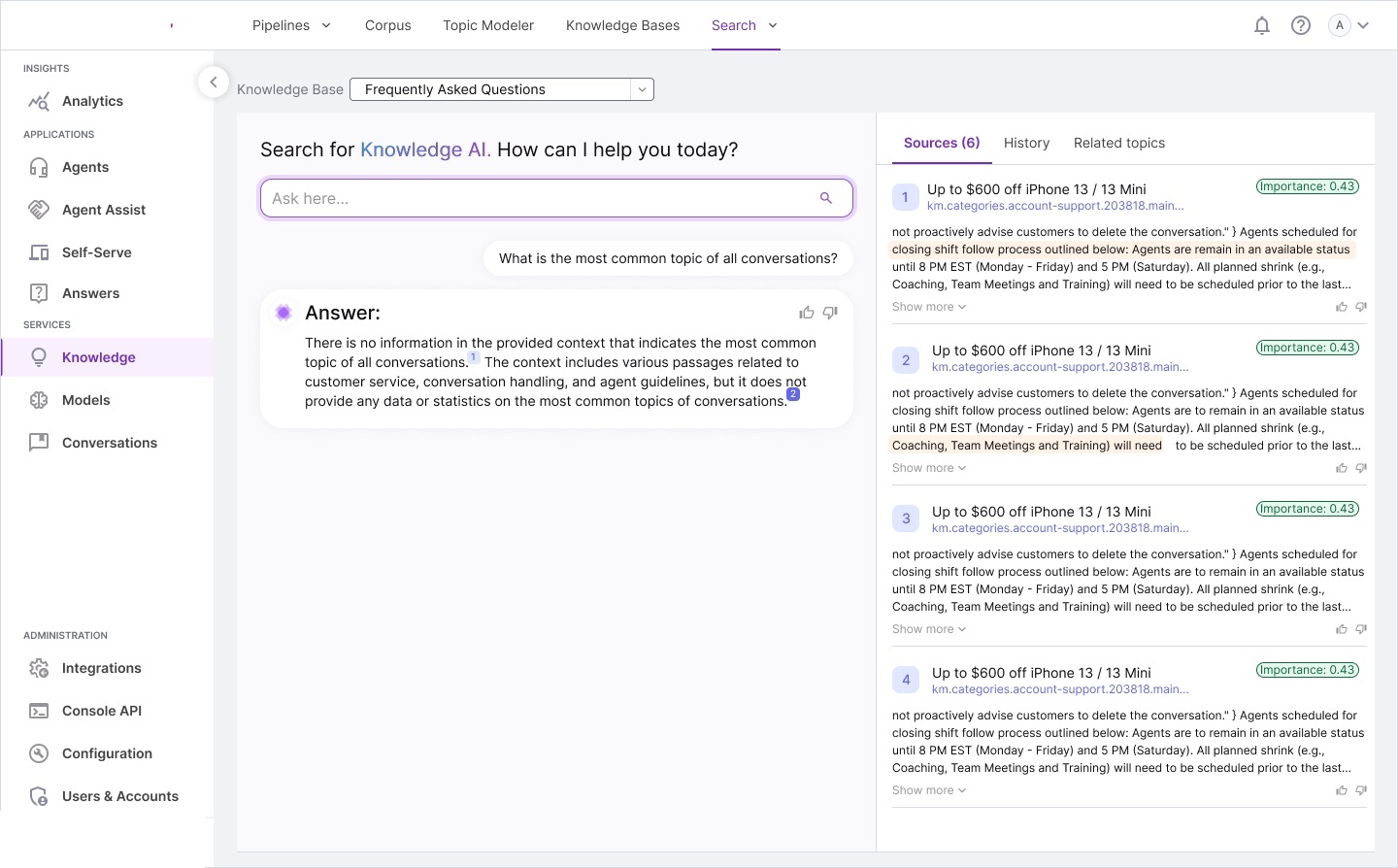
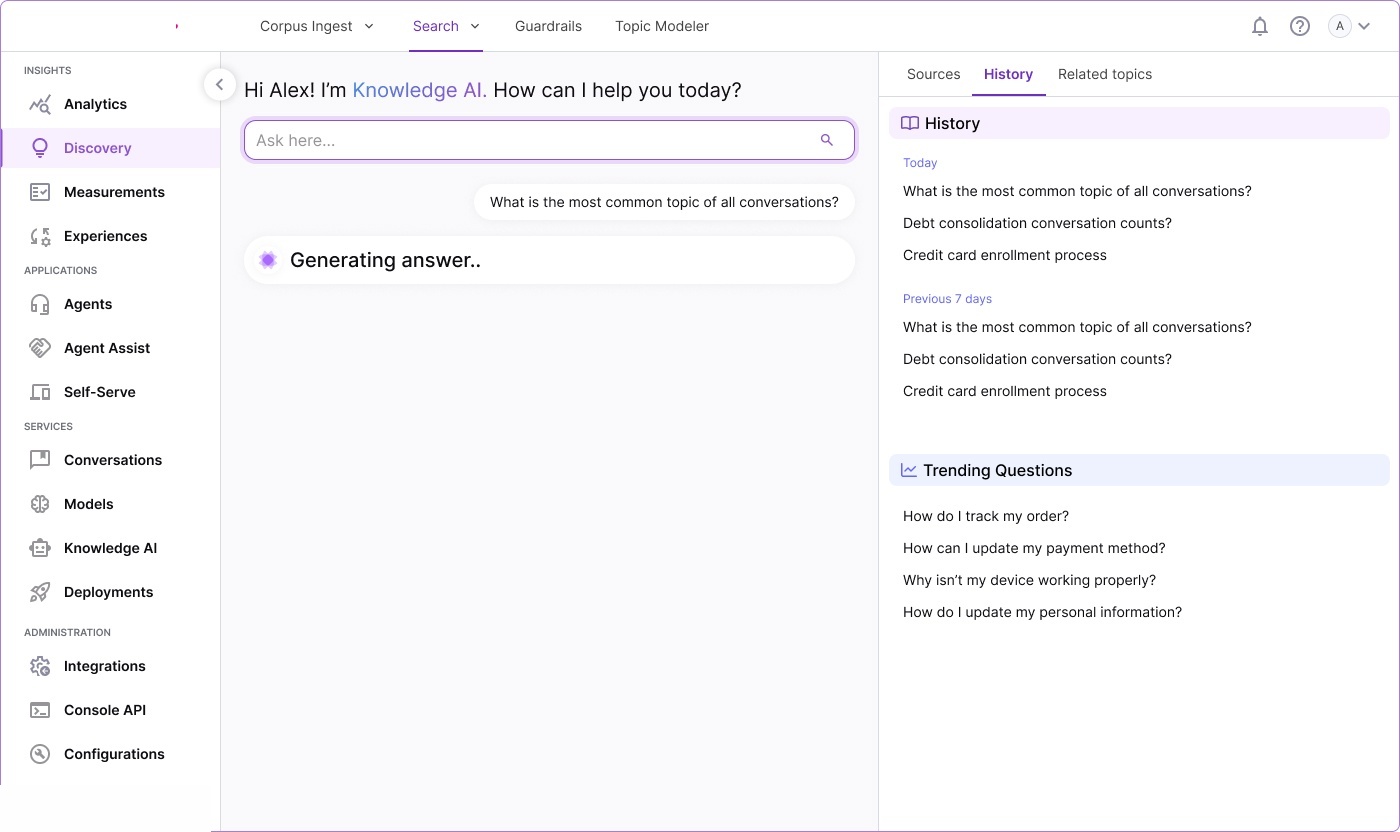
Workflow storyboards — pipeline architecture, corpus processing models,
annotated requirements, and interaction specifications for each module.